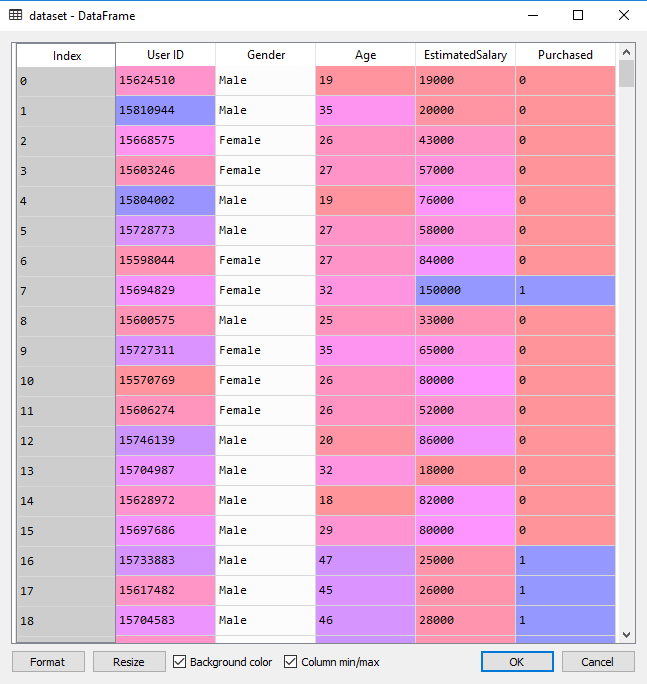
随机森林
导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
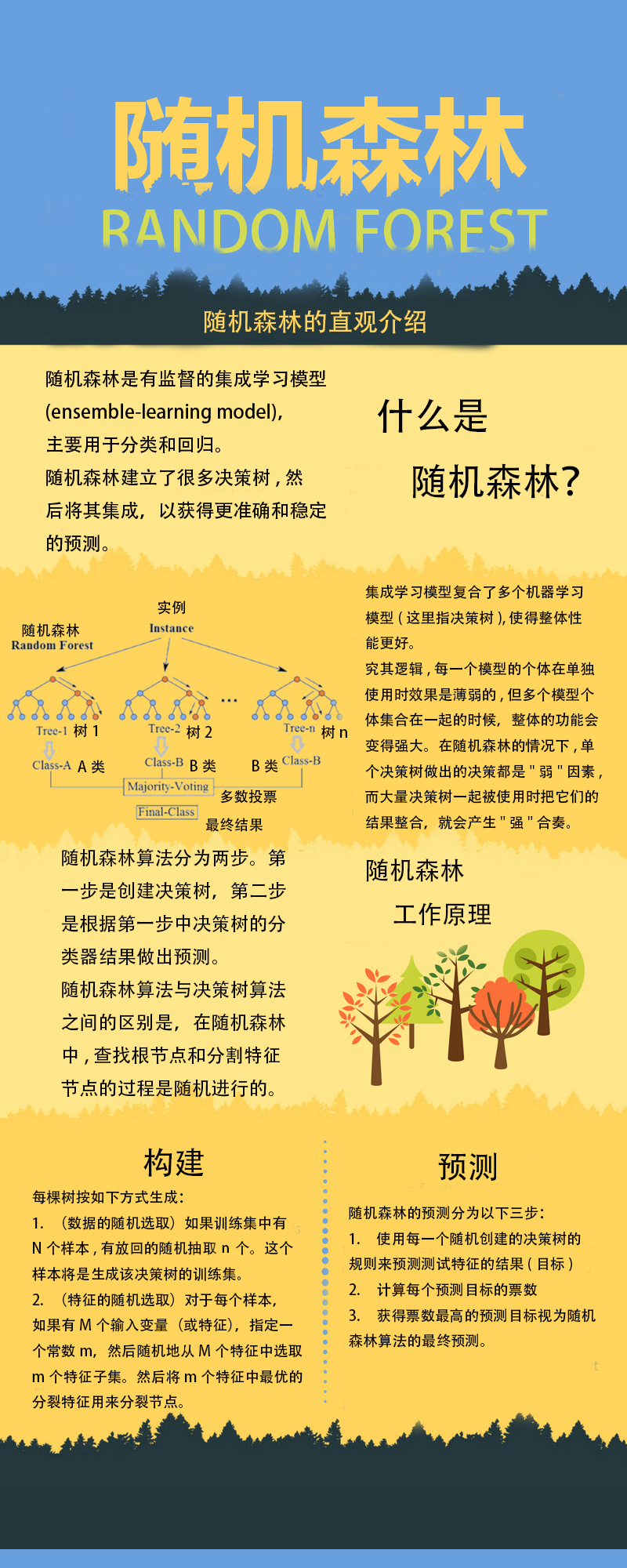
导入数据集
dataset = pd.read_csv('../datasets/Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
将数据集拆分成训练集和测试集
from sklearn.model_selection import train_test_split
X_tr...